Airflow and DBT Analytics Accelerator
An Open-source accelerator for a ready-to-run, end-to-end analytics platform
0.0
0 reviews•
Apache Airflow·
dbt·
ClickHouse·
SQL·
AWS
DBT-ClickHouse-Accelerator is an open-source analytics accelerator that provides a ready-to-run, end-to-end data analytics platform built using modern data engineering tools. The project demonstrates...
About this project
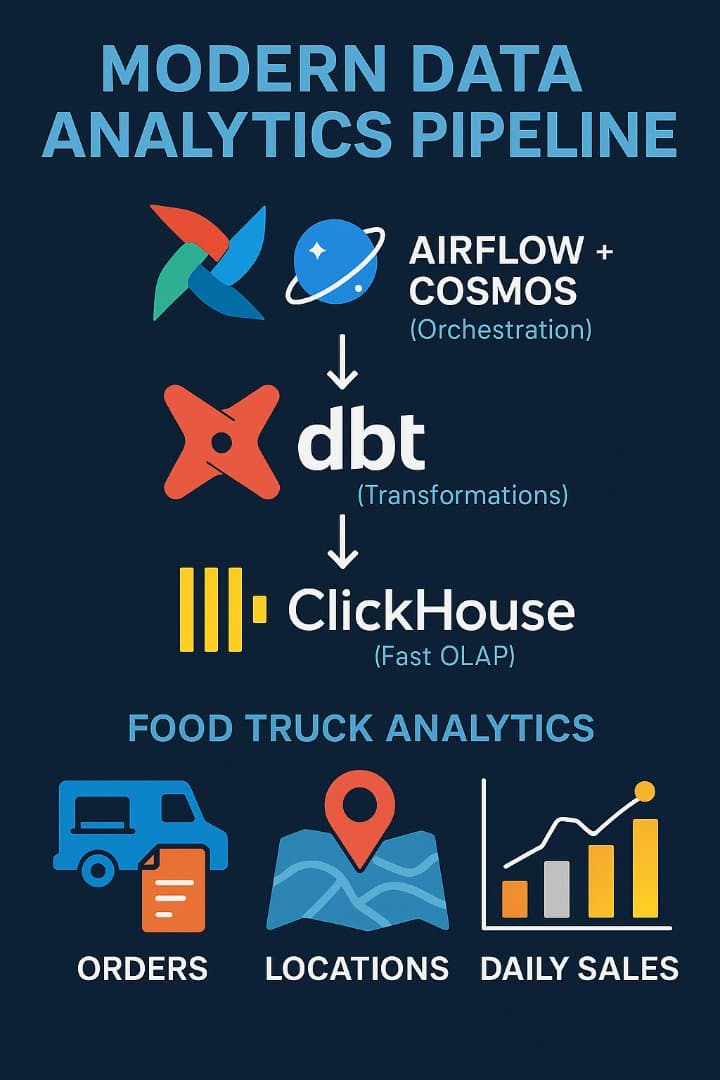
DBT-ClickHouse-Accelerator is an open-source analytics accelerator that provides a ready-to-run, end-to-end data analytics platform built using modern data engineering tools. The project demonstrates how to design, orchestrate, and scale analytical data pipelines using ClickHouse, DBT, and Apache Airflow with Cosmos.
At its core, the accelerator showcases a layered analytics architecture (Bronze, Silver, Gold) where raw data is ingested into ClickHouse and progressively transformed into clean, business-ready datasets using DBT SQL models. These transformations are orchestrated through Airflow DAGs powered by Cosmos, enabling seamless scheduling, dependency management, and observability of DBT workflows.
The project includes a Food Truck Analytics use case, modeling real-world business scenarios such as orders, locations, and daily sales metrics. It comes with preconfigured DBT models, seeds, tests, and ClickHouse integrations, allowing users to quickly spin up a working analytics environment locally using Astro.
This accelerator is ideal for data engineers and analytics teams who want to:
Learn how DBT integrates with ClickHouse
Implement orchestration best practices with Airflow
Prototype analytical pipelines quickly
Build high-performance OLAP analytics on modern infrastructure
Overall, DBT-ClickHouse-Accelerator serves as both a learning reference and a practical foundation for building scalable, production-grade analytics platforms.